2022. 2. 2. 13:17ㆍNLP
최근 핫한 주제인 Transformer을 제시한 논문 Attention Is All You Need에 대해서 리뷰해보겠습니다! 2017년 Goolge은 논문 Attention Is All You Need을 발표했습니다. 기존의 지배적인 sequence transduction 모델은 인코더와 디코더를 attention을 통해 연결한 RNN 또는 CNN 구조였습니다. 본 논문에서는 RNN과 CNN을 사용하지 않고 오직 attention에 기반한 simple network 아키텍쳐를 제시합니다. 두가지 머신번역 태스크에서 우월한 성능을 보여주고, 병렬화(parallelizable)을 통해 학습에 필요한 시간이 줄어들었음을 보여줍니다.
Introduction
RNN, LSTM, Gated RNN은 sequence 모델링에서 SOTA였습니다.
1. Recurrent models
Recurrent 모델은 일반적으로 input과 output의 sequence의 토큰 위치에 따라 factor computation을 합니다. 각 t개의 시점(time step)에 따라 위치를 정렬 시키고 이전 시점의 hidden layer인 h_t-1과 현재 시점의 input으로 현재 시점의 hidden layer인 h_t를 도출합니다. 연속적으로 이어지기 때문에 학습 데이터에서 병렬화를 못해 긴 sequence에서 한계가 있습니다.
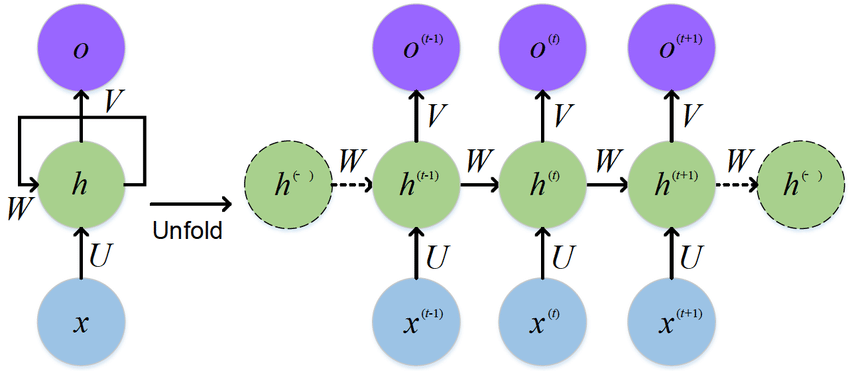
2. Attention mechanisms
Attention은 input 또는 output의 sequence 거리에 상관없이 단어 간의 관계를 연결할 수 있어 다양한 task의 sequence 모델링과 transduction 모델에서 중요한 역할을 하고 있습니다. 이러한 Attention은 대부분의 경우 recurrent 모델과 결합되어 사용됩니다.
3. Transformer
본 논문에서 제시한 모델로 recurrence를 제거하고 전적으로 attention에 의존해 input과 output의 관계를 추출합니다. 병렬화가 가능하고 새로운 SOTA에 도달할 수 있습니다.
Background
Extended Neural GPU, ByteNet, ConvS2S은 Sequential 계산을 줄이는 것을 목표로 형성된 모델입니다. Convolution neural network에 기반한 모델로 멀리 떨어져 있는 position 간의 관계를 학습하기가 어려웠습니다. Transformer에서는 상수 시간의 계산으로 줄여주었습니다. 비록 attention-weighted을 평균해 유효 해상도가 감소한다는 문제가 있지만 이것은 추후 설명할 Multi-Head Attention을 통해 해결할 수 있습니다.
Self-attention은 한 sequence의 representation을 계산하기 위한 단일 sequence의 다른 positions를 관련시키는 attention 매커니즘입니다. 글 이해력, 추상적 요약 등 다양한 태스크에서 성공적으로 사용되고 있습니다.
End-to-end memory networks는 recurrent attention mechanism에 기반하고 있습니다. simple-language question answering과 언어 모델 태스크에서 좋은 성능을 보여줬습니다.
Transformer는 RNN 또는 CNN을 사용하지 않고 전적으로 self-attention에 기반해 input과 output의 representation을 계산한 변환(transduction) 모델입니다.
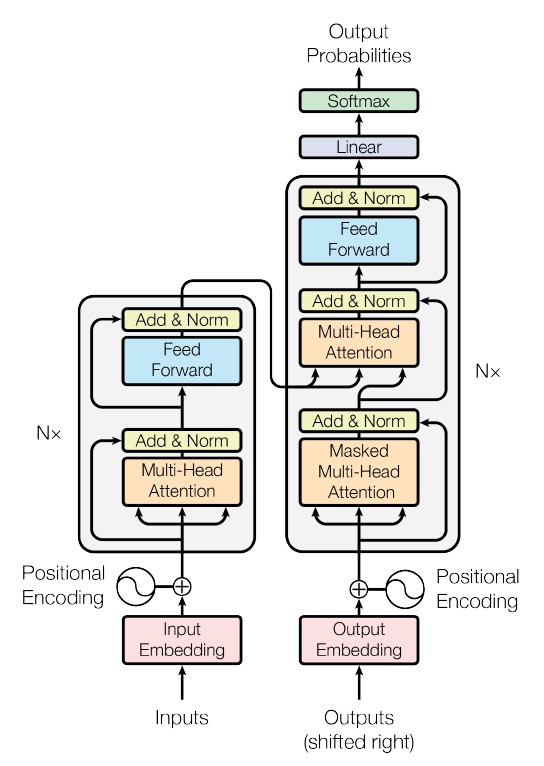
Model Architecture
인코더-디코더 구조에서 인코더는 입력 sequence (x1, ... ,xn)를 받아 continuous representation z = (z1, ... ,zn)을 반환하고, 디코더는 이 z를 사용해 출력 sequence (y1, ... ,yn)을 생성합니다. 이때 각 time step에서 다음 단어입력을 생성할 때, 모델은 이전에 생성된 단어를 추가적인 input으로써 사용하기 때문에 Auto-Regressive합니다.
Transformer도 이러한 전반적인 아키텍쳐를 따릅니다. 인코더와 디코더에 stacked self-attention, point-wise, fully connected layer를 사용합니다.
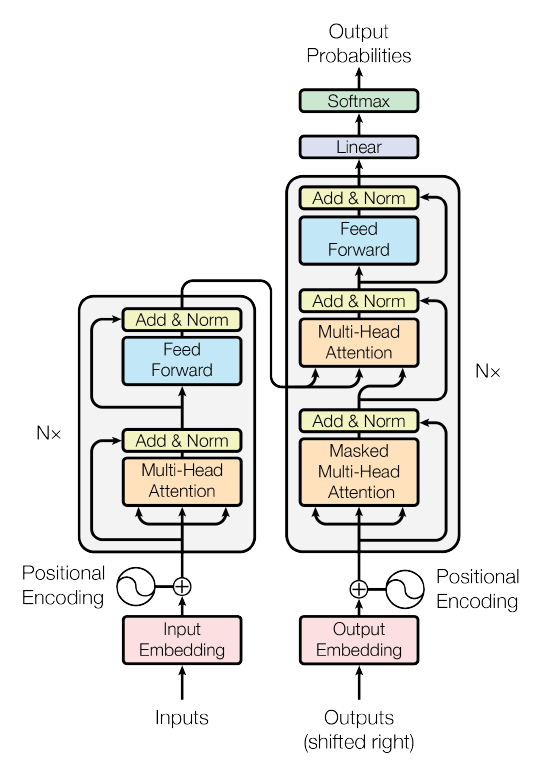
1. Encoder and Decoder Stacks
(1) Encoder
위 그림에서 왼쪽에 해당하는 것으로 인코더 6개의 (N=6) 동일한 레이어를 stack해 구성합니다. 각 레이어에는 2개의 sub-layers 가 있습니다.
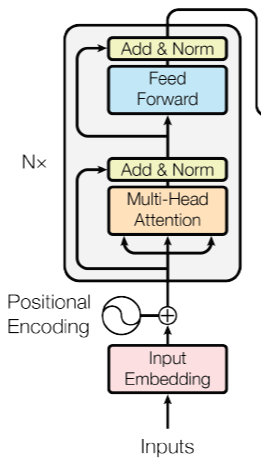
첫번째 sub-layer : multi-head self- attention mechanism
두번째 sub-layer : simple position-wise fully connected feed-forward network
그림에서 Add & Norm 에 해당하는 부분으로 두개의 sub-layer 각각에 잔차연결(residual connection)과 층 정규화(layer normalization)을 사용합니다. 잔차연결은 x + Sublayer(x), 즉 sub-layer 층의 입력과 출력을 더하는 과정입니다. 따라서 sub-layer와 임베딩 레이어의 출력과 입력의 차원은 동일해야합니다(d_model = 512). 그리고 층 정규화를 적용해, 최종 함수는 LayerNorm(x + Sublayer(x)) 입니다.
(2) Decoder
위 그림에서 오른쪽에 해당하는 것으로 마찬가지로 디코더 6개의 (N=6) 동일한 레이어를 stack해 구성합니다. 인코더의 2개의 sub-layer와 더불어 sublayer인 인코더의 출력에 대한 Masked multi-head self-attention을 추가합니다. 뒤에 오는 단어를 참고하지 못하도록 masking을 사용했습니다. 즉 i 시점의 단어가 오직 i 이전의 단어에만 의존하도록 했습니다. 또한 각 sub-layer에 대해 잔차연결과 층 정규화를 사용합니다.
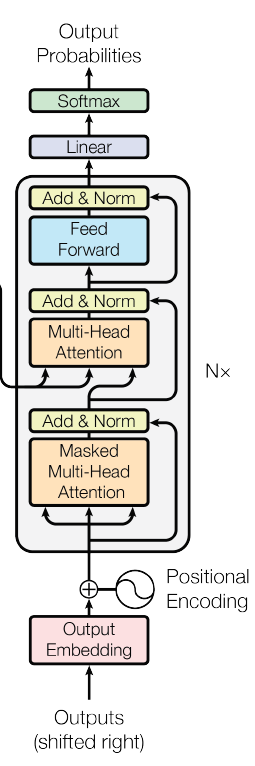
2. Attention
Attention은 query에 대해서 key-value 쌍을 출력과 mapping합니다. 여기서 Query, Keys, Values 그리고 출력은 모두 벡터입니다. Query에서 모든 key와의 유사도를 구하고, key에 해당하는 각 value를 유사도 가중합으로 출력이 계산됩니다. Query, Keys, Values는 입력 sequence의 모든 단어 벡터들입니다.
(1) Scaled Dot- Product Attention
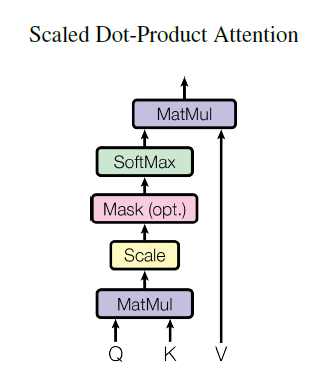
입력은 queries, 차원이 d_k인 keys, 차원이 d_v인 values로 구성되어 있습니다. 가중치를 얻기 위해 softmax function을 적용합니다. key의 차원, d_k에 루트를 씌운 값으로 나누어줘 스케일링해줍니다. 이때 각 query 벡터를 따로 계산하는 것이 아니라 query 집합으로 동시에 계산합니다. 따라서 queries, keys, values는 각각 행렬 Q, K, V가 됩니다. 최종 출력식은 다음과 같습니다.
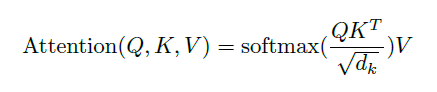
일반적으로 자주 사용되는 attention 함수에는 Additive attention과 본 모델에 사용한 Dot-product attetion이 있습니다. 두 방법의 이론상 복잡성은 비슷하지만 실제 적용에서 Dot-product attention이 휠씬 빠르고 더 space-efficient 합니다. 최적화된 행렬 곱 code를 구현할 수 있기 때문입니다.
(2) Multi-Head Attention
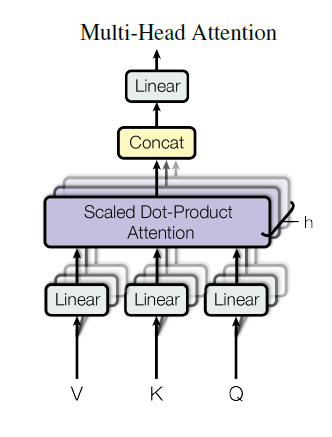
d_model 차원의 queries, keys, values을 사용한 한번의 attention 함수보다 각각 d_v, d_k, d_k 차원으로 축소해 서로 다른 h개의 linear projection을 한 것이 더 효과적이라는 것을 알아냈습니다. 차원을 축소한 V, K, Q를 병렬 attention을 적용합니다. 결과적으로 d_v차원의 출력 값이 만들어집니다. 이것이 합쳐져(concatenated) 다시 투영(projection)해 최종 값을 얻을 수 있습니다.
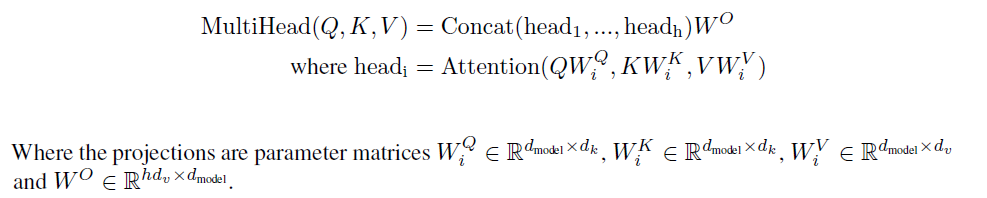
이는 서로 다른 positions에 서로 다른 representation subspaces에서 결합적으로(jointly) 정보에 접근할 수 있도록 합니다. 즉 축소된 Attention을 병렬화해 다양한 시각으로 정보를 수집할 수 있습니다.
본 논문에서 8개의 parallel attention layers(h=8)을, 각 d_k, d_v는 64차원(512/8=64)을 사용했습니다.
(3) Applications of Attention in our Model
Transformer은 multi-head attention을 3가지 방법으로 사용했습니다.
- 디코더의 두번째 sub-layer, Multi-Head Attention에 사용되었습니다. "encoder-decoder attention" 레이어에서 queries는 이전의 디코더 레이어에서 오고 memory keys와 values는 인코더의 출력으로부터 옵니다. 이것은 디코더가 입력 sequence의 모든 position을 고려할 수 있도록 합니다. 이는 sequence-to-sequence 모델의 일반적인 인코더-디코더 attention 매커니즘을 모방한 것입니다.
- 인코더의 첫번째 sub-layer, Multi-Head Attntion에 사용되었습니다. 인코더는 self-attention layers를 포함합니다. self-attention layer에서 모든 key, values, queries는 같은 곳(인코더의 이전 레이어의 출력)에서 옵니다. 인코더의 각 position은 이전 레이어의 모든 position을 고려할 수 있습니다.
- 디코더의 첫번째 sub-layer, Masked Multi-Head Attention에 사용되었습니다. 디코더의 self-attention layer로 디코더가 해당 position과 이전까지의 positon만을 고려할 수 있도록 합니다. 현재 position 다음의 position을 masking out합니다. 아주 작은 값에 수렴하도록 값을 주고 softmax를 적용하는 방법으로 미래의 position에 대한 영향을 maskong out할 수 있습니다.
3. Position-wise Feed-Forward Networks
인코더와 디코더의 각 레이어는 Fully Connected feed-forward network을 포함합니다. 각 position에 독립적으로 동일하게 적용됩니다. 이것은 두개의 선형변환과 ReLU로 이루어져 있습니다.
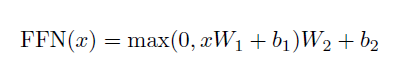
하나의 층 내에서 다른 position에 대해 선형변환은 같지만, 레이어마다는 다른 모수를 사용합니다. 입력과 출력의 차원은 d_model = 512, 그리고 inner-layer의 차원은 d_ff = 2048입니다.
4. Embeddings and Softmax
다른 sequence 변환과 비슷하게, transformer도 입력 토큰과 출력 토큰을 차원이 d_model인 벡터로 전환하기 위해 learned embedding을 사용합니다. 디코더의 출력으로 next-token 확률을 예측하기 위해 학습가능한 선형변환과 소프트맥스 함수 사용합니다. 두 임베딩 레이어와 pre-softmax 선형 변환에서 동일한 weight 행렬을 공유합니다. 임베딩 레이어에서 이 가중치들에 d_model 루트 씌운 값을 곱해 사용합니다.
5. Positional Encoding
Transformer는 RNN과 CNN을 사용하지 않기 때문에 sequence의 순서를 반영하기 위해서 단어 토큰의 상대적 또는 절대적 위치에 대한 정보를 삽입하는 것이 필요합니다. 따라서 인코더와 디코더의 입력 임베딩에 "Positional Encoding"을 추가했습니다. Positional Encoding은 임베딩의 차원과 마찬가지로 d_model 차원을 갖게 해 두개간의 덧셈을 가능하게 합니다. 위치 정보를 가진 값을 만들기 위해 다음 두 함수를 사용합니다.
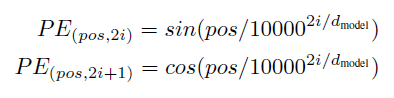
pos : 위치 (position)
i : 차원(dimension)
각 위치 인코딩의 차원은 사인곡선(sinusoid)에 대응됩니다. 인덱스가 짝수(2i)일 때는 사인함수를 사용하고 홀수(2i+1)일 때는 코사인 함수를 사용합니다. 어느 k 값이라도 PE_(pos+k)는 선형 함수 PE_(pos)로 나타날 수 있기 때문에 사인·코사인 함수를 선택했습니다.
Learning positional embedding 방법도 거의 비슷한 결과를 보여주지만, 사인곡선의 방법이 학습과정에서 만났던 sequence 보다 긴 sequence에 대해서도 추론할 수 있기 때문에 사용했습니다.
Conclusion
본 논문에서는 recurrence와 convolution을 모두 제거한, 오직 Attention에 기반한 첫번째 sequence transduction 모델인 Transformer를 제시합니다.
번역 task에서 transformer는 RNN, CNN에 기반한 다른 아키텍쳐보다 휠씬 더 빠르게 학습됩니다. WMT 2014 EN to GM, EN to FR 번역 테스크에서 SOTA를 달성했습니다. 또한 이전에 발표된 모델들의 앙상블보다도 성능이 좋았습니다.
attention-based 모델의 미래가 기대됩니다! 저자들은 attention-based 모델을 다른 task에 적용하고 입출력 데이터가 텍스트 뿐만 아니라 이미지, 오디오, 비디오와 같은 큰 입출력을 효율적으로 다룰수 있도록 하는 Attention 매커니즘에 대해서 연구할 계획이라고 합니다.
'NLP' 카테고리의 다른 글
| 한국어 문장 관계 분류 모델 : RoBERTa+KoELECTRA+Backtrans (0) | 2022.03.18 |
|---|---|
| BERT 논문 리뷰 : Pre-training of Deep Bidirectional Transformers for Language Unders (0) | 2022.02.11 |
| Fasttext 논문 리뷰 : Enriching Word Vectors with Subword Information (0) | 2022.01.22 |
| GloVe 논문 리뷰 : Global Vectors forWord Representation (0) | 2022.01.16 |
| Skip-gram 코드 구현 : Word2Vec의 Skip-gram 모델 구현 (0) | 2022.01.10 |