2022. 1. 22. 17:52ㆍNLP
오늘은 Word2Vec 모델을 기반으로 하는 논문 Fasttext에 대해서 리뷰해보겠습니다. 2017년 Facebook은 논문 Enriching Word Vectors with Subword Informationd을 발표했습니다. 기존의 단어 임베딩 모델이 각 단어에 별개의 벡터를 부여하면서 단어의 형태론 무시한다는 한계가 있었습니다. 특히 rare words가 많은 large vocabularies에 문제가 되었습니다. 따라서 본 논문에서 skipgram 모델에 기반한 새로운 접근방법 Fasttext를 제시합니다.
Fasttext에서 각 단어는 n-gram의 구성으로 표현됩니다. 이 모델은 이름에서 알 수 있듯이 학습 속도가 빠르고, 학습데이터에 등장하지 않은 단어에 대해서도 단어벡터이 표현가능합니다. 단어유사도, 유추 task에 실험결과 이전 모델보다 SOTA 성능을 보여줍니다.
Introduction
대부분의 이전 모델은 각 단어를 별개의 벡터로 나타내 단어의 내부적인 구조를 무시했습니다. 그러나 character level information을 사용한다면 형태론적으로 의미가 풍부한 언어의 단어 벡터 표현을 향상 시킬 수 있습니다. 본 논문에서 skip-gram 모델을 확장해 n-grams으로 각 단어를 나타내는 방법을 소개합니다.
Related work
1. Morphological word representations
factored neural language models는 단어의 특징 모음(set of features)으로 표현됩니다. 이 특징에는 형태론적 정보도 포함됩니다. 이러한 모델은 단어의 형태론적 분해에 의존합니다. 또한 형태론적 변환을 통해서 이전에 못 본 단어를 표현하고자 했습니다. Wieting et al.(2016)는 Fasttext 모델과 유사하게 n-gram 빈도 벡터로 나타냅니다. 하지만 paraphrase pairs에만 학습된다는 한계가 있었고 Fasttex는 어느 텍스트 코퍼스에도 학습될 수 있습니다.
2. Character level features for NLP
character로부터 언어 표현을 학습합니다. 감성분석, 텍스트 분류, 언어모델링 등 다양하게 적용될 수 있습니다.
Model
subword를 통해 형태론적 정보를 고려해 단어 벡터를 학습하는 모델을 제시합니다. subword를 고려하고 n-gram 벡터 합을 통해서 단어벡터를 나타냅니다.
1. General model
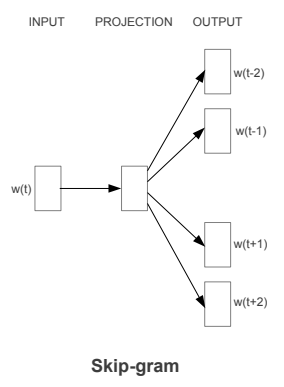
general model은 skipgram model with negative sampling 입니다. distributional hypothesis을 통해서 context에 등장할 단어를 잘 예측한 단어(predict well)로 나타내도록 단어벡터를 학습합니다. 즉 skip-gram 모델은 다음과 같은 로그우도함수를 최대화하고자 합니다. 단어 총 T개에 대해서 중심단어가 주어질때, 주변단어가 나올 확률이 최대화가 되도록 학습합니다.
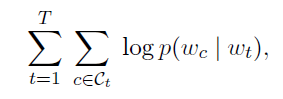
W : word vocabulary size
w : word's index
w_t : 중심단어
w_c : 주변단어 (context words)
C_t : 중심단어 w_t의 주변단어의 집합
context words의 softmax probability

s : scoring function
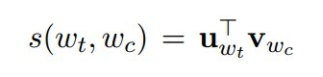
그러나 이 확률은 하나의 주변단어 w_c만 예측하기 때문에 주변단어 여러개를 예측하는 경우에 적용할 수 없습니다. 따라서 negative sampling을 사용합니다. negative sampling은 주변단어(context words)를 제외한 윈도우 밖의 단어를 sampling하여 Context words를 예측하는 multi label classification이 아닌, context words 인지, 아닌지를 예측하는 binary classification 문제로 objective function을 치환합니다.

N_t,c : set of negative examples
w_t가 주어졌을 때 w_c가 정답이면 이 두 벡터의 유사도를 높게 만들고 실제 정답이 아닌 n에 대해서는 유사도가 낮도록 합니다.
2. Subword model
subword를 고려해 형태론적 정보를 나타낼 수 있습니다. 기호 < 그리고 > 를 단어의 시작과 끝 부분에 추가합니다.
- 단어 where, n = 3 일때
<wh, whe, her, ere, re>, <where>
여기서 her은 단어 her의 <her>과 다릅니다. 실제 사용할 때는 기본 최소 n=3, 최대 n=6 범위에서 사용합니다. (범위는 변경할 수 있습니다.)
3 grams : <wh, whe, her, ere, re>
4 grams : <whe, wher, here, ere>
5 grams : <wher, where, here>
6 grams : <where, where>
vector(where) = vector(<wh) + vector(whe) + ... + vector(<where) + vector(where>)
단어는 subword 벡터의 합으로 나타냅니다. 따라서 scoring function은 다음과 같이 얻을 수 있습니다.
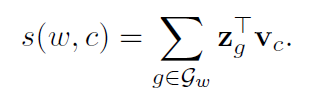
z_g : 각 n-gram g의 단어 벡터
모르는 단어(Out Of Vocabulary, OOV)에 대한 학습 능력이 향상되고 오타나 빈도수가 낮은 데이터에 대해서도 학습이 가능해졌습니다.
Experiment
5개의 experiments를 통해 모델을 평가했습니다. 본 논문의 모델은 sisg(Subword Information Skip Gram)로 나타냈습니다.
1. 사람의 유사도 평가와 단어 벡터의 유사도의 correlation 비교
cbow와 skipgram(cbow and sg)은 학습데이터에 나타나지 않은 단어에 대해서 단어 벡터를 도출할 수 없기 때문에 이 단어에 대해서는 null vector(sisg-)를 만들었습니다. 본 논문의 모델(sisg, Subword Information Skip Gram)은 subword 정보를 사용하기 때문에 모르는 단어(OOV)에 대해서도 타당한 단어벡터를 나타낼 수 있습니다.
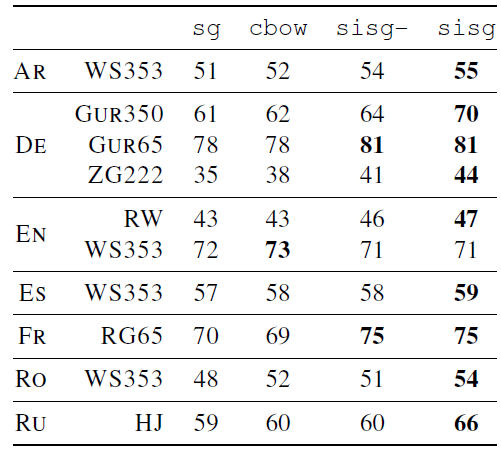
English WS353을 제외하고 모든 데이터에서 baseline보다 sisg가 성능이 좋은 것으로 나타났습니다. 또 모르는 단어를 단어벡터로 나타낸 sisg가 null로 나타낸 sisg-보다 같거나 더 좋은 성능을 보여줘 subword 정보의 장점을 증명해줍니다.
Arabic, German 그리고 Russian이 다른 언어보다 더 효과적인 것으로 나타났습니다. German은 4가지 Russian은 6가지 문법적 어형변화를 보이고 Russian은 합성어가 많기 때문에 형태론적 정보가 중요하기 때문인 것으로 보입니다.
English에서 Rare Words dataset (RW)는 좋은 성능을 보이지만 WS353에서는 낮게 나타나냈습니다. 이것은 이 데이터 셋에서 자주 등장하는 단어로 구성되어있어 subword 정보가 중요하지 않았기 때문입니다.
2. 유추 문제 Word analogy
A : B = C : D의 관계 에서 모델을 통해 D를 예측하는 것이 목표입니다. 학습데이터에 나타나지 않은 단어가 포함된 questions은 제외했습니다.
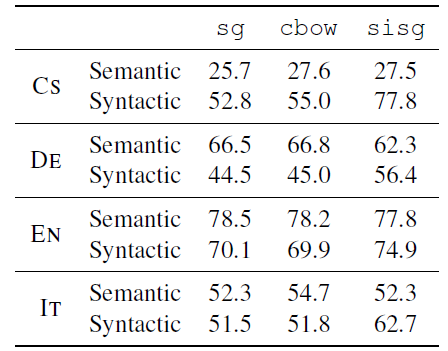
syntactic information에서 뚜렷한 성능 개선을 보여줍니다. 대조적으로 semantic에서는 성능 개선이 나타나지 않았습니다. 그러나 이후에 나올 실험(5)에서 보여주듯이 character n-gram의 길이 조정을 통해서 semantic에서도 성능을 개선할 수 있었습니다. 형태론적 정보가 풍부한 Czech(CS) 그리고 German(DE)에서 우수한 성능을 보였습니다.
3. Comparison with morphological representations
RNN, cbow, morphological transformation of Soricut and Och, log-bilinear language 모델을 본 논문에서 제시한 모델 sisg와 유사성 task에 대해 비교했습니다.
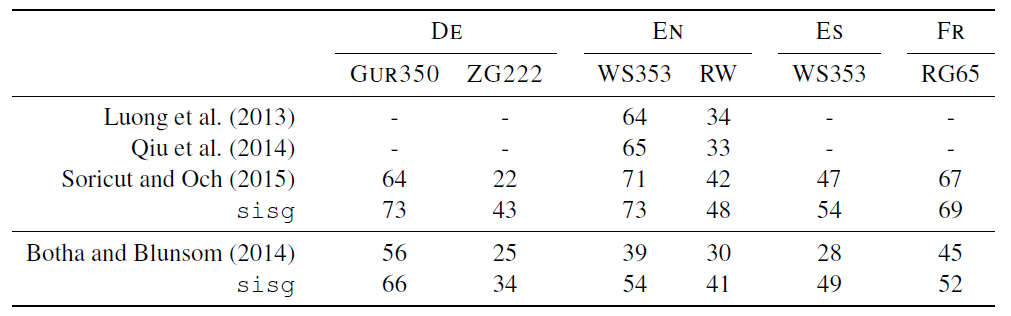
형태론적 정보에 기반한 모델로 우수한 성능을 가지고 있습니다. 또 형태론적 변환을 사용한 Soricut and Och(2015)보다도 좋은 성능을 보여줍니다. 특히 German에서 큰 개선을 보여줍니다. Soricut and Och(2015)에서는 noun compounding을 하지 않았기 때문입니다.
4. Effect of the size of the training data
우리는 단어간의 character-level 유사성을 이용하기 때문에 자주 등장하지 않는 단어에 대해서도 잘 학습시킬 수 있습니다. 따라서 학습데이터의 사이즈에 robust 해야합니다. OOV의 비율은 데이터셋이 줄어들수록 증가할 것입니다. 따라서 sisg-와 cbow는 성능이 상대적으로 낮을 것 입니다. 단어 사이즈에 의존하는지 평가하기 위해 cbow 모델과 비교했습니다.
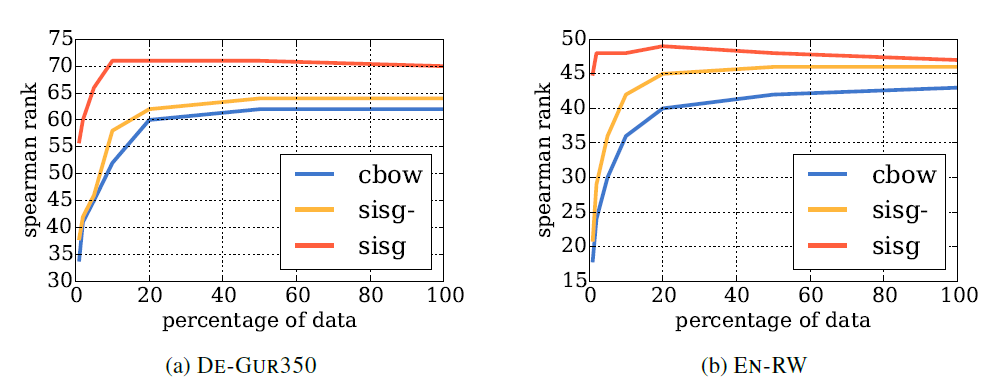
결과, 모든 데이터셋에서, 모든 사이즈에서 sisg가 높은 성능을 보입니다. cbow 모델은 데이터 사이즈가 증가할 수록 좋은 성능을 보이는 반면에 sisg는 데이터 사이즈의 증가가 항상 성능 증가를 불러오지는 않았습니다. 아주 작은 학습데이터셋에도 sisg는 높은 성능을 보였습니다. German GUR350에서 sisg가 데이터셋의 5%만 사용했을 때 성능은 66으로 cbow로 전체 데이터셋에서 학습한 성능 62보다 높았습니다. 또한 English RW에서 sisg가 데이터셋의 1%만 사용했을 때 성능은 45으로 cbow로 전체 데이터셋에서 학습한 성능 43보다 높았습니다.따라서 제한된 사이즈의 데이터 셋에서도 단어벡터가 학습될 수 있고 이전에 등장하지 않은 단어에 대해서도 여전히 잘 학습된다는 것을 의미합니다. 일반적으로 활용에 필요한 relevent task-specific data는 양이 많지 않은데, 이 모델을 통해 적은 학습데이터로 학습할 수 있다는 것은 큰 장점입니다.
5. Effect of the size of n-grams
앞서 모델에서 설명했듯이 n-gram의 기본 size을 3-6으로 설정했습니다. n size가 어떤 영향을 주는지 알아보기 위해 실험을 진행한 결과 다음과 같습니다.
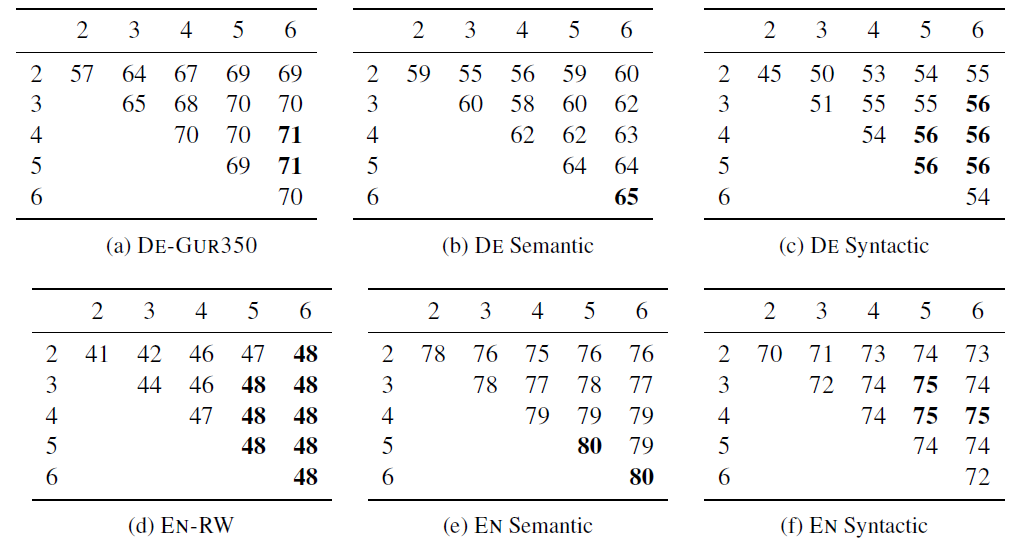
English 그리고 German에서 3-6은 합리적인 선택이었음을 보여줍니다. 범위의 길이는 task와 language에 따라 임의적으로 조정해야합니다. long n-gram을 포함하는 것이 중요하다는 것을 보여줍니다. 열5, 6에서 가장 좋은 결과가 나타났습니다. 유추 task에서 longer n-grams가 semantic 유추를 도와줍니다. n-gram을 사용할 때, 기호 <, >를 사용했기 때문에 n = 2로 하면 하나는 proper character이고 다른 하나는 positional one인 것이 생기기 때문에 2보다는 커야한다는 것을 알 수 있습니다.
6. Language modeling
without using pre-trained word vectors (LSTM), with pre-trained word vectors without subword information(sg), 그리고 논문에서 제시한 모델(sisg)을 비교했습니다.
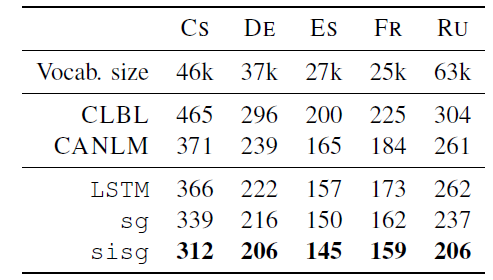
pre-trained word vectors일 때 test perplexit가 개선되었습니다. subword를 사용했을 때, plain skipgram model보다 더 낮은 test perplexit을 보여줍니다.
Oualitative analysis
1. 자주 등장하지 않는 단어에 대한 Nearest neighbors
코사인 유사도를 통해 자주 등장하지 않은 단어에 대한 Nearest neighbors는 다음과 같습니다. 베이스라인인 skipgram보다 본 모델(sisg)이 더 잘 나타났습니다.

2. Character n-grams and morphemes
각 단어의 중요한 n-gram을 찾고자 합니다. w은 단어의 n-grams의 합이고 각 n-gram g에 대해서 restricted representation을 정의합니다.
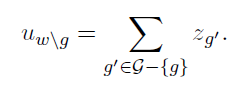
u_w와 u_w/g간의 코사인 값의 오름차순으로 n-gram을 순위를 정합니다. ranked n-grams는 다음 표로 보여줍니다.

예를 들어 Autofahrer (car driver)의 중요한 n-grams는 Auto (car) 그리고 Fahrer (driver)로 합리적인 결과입니다. 또한 starfish은 star과 fish, lifetime은 life와 time이 도출되었습니다.
3. Word similarity for OOV words
본 논문의 모델은 OOV에 대한 단어 벡터를 만드는 것이 가능합니다. OOV 단어의 n-grams 평균으로 vector representation을 구합니다. 이 단어 벡터가 단어의 의미를 잘 나타내는지 평가하기 위해 하나의 OOV 단어와 학습데이터 내의 단어를 pair로 두 단어간의 코사인 유사도를 구했습니다.
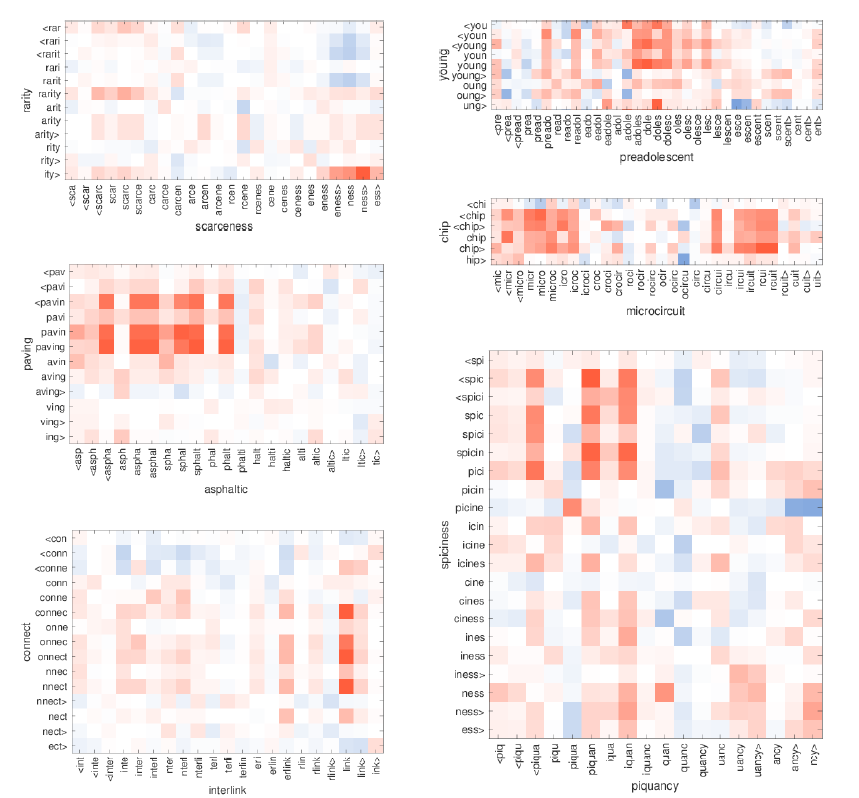
다음 그림에서 x축이 OOV 단어입니다. 빨간색은 양의 코사인, 파란색은 음의 코사인을 의미합니다.
단어 rarity와 scarceness에서 -ness와 -ity가 높은 유사도를 보입니다. 또한 단어 preadolescent는 -adolesc-라는 subword 덕분에 단어 young과 잘 매치됩니다. 따라서 OOV 단어도 의미를 잘 나타내는 단어벡터를 만들 수 있습니다.
Conclusion
subword 정보를 통해 단어벡터를 나타내는 방법을 소개했습니다. Fasttext는 character n-grams과 skipgram을 결합한 모델입니다. 이 모델은 학습을 빠르게 하고 사전처리나 감독이 필요하지 않다는 장점이 있습니다. 결론적으로 다양한 task에서 베이스라인을 뛰어넘는 성능을 보여주고 형태론적 정보를 포함하는 모델입니다.
References
Enriching Word Vectors with Subword Information (Piotr Bojanowski, Edouard Grave, Armand Joulin, Tomas Mikolov)
'NLP' 카테고리의 다른 글
| BERT 논문 리뷰 : Pre-training of Deep Bidirectional Transformers for Language Unders (0) | 2022.02.11 |
|---|---|
| Transformer 논문 리뷰 : Attention Is All You Need (0) | 2022.02.02 |
| GloVe 논문 리뷰 : Global Vectors forWord Representation (0) | 2022.01.16 |
| Skip-gram 코드 구현 : Word2Vec의 Skip-gram 모델 구현 (0) | 2022.01.10 |
| CBOW 코드 구현 : Word2Vec의 CBOW 모델 구현 (0) | 2022.01.07 |