2022. 4. 23. 14:47ㆍCV
NLP와 CV를 연결하는 Image Captioning의 모델을 소개하겠습니다. Image Captioning은 이미지의 내용을 설명하는 문장을 생성하는 것으로 CV와 NLP를 연결하는 인공지능 분야입니다. show and tell은 2015년 Google은 발표한 논문입니다. 이 논문에서는 CV와 머신번역을 결합한 deep recurrent 구조를 사용합니다. 이 모델은 training image가 주어졌을 때, target description의 likelihood를 최대화하는 방향으로 학습합니다.
Introduction
기존의 CV에서 주된 목표였던 이미지 classification이나 object recognition문제보다 어려운 문제를 가지고 있습니다. 이미지에 들어있는 물체는 인식하는 것 뿐만아니라 그들의 특성, 활동, 그리고 다른 물체와의 관계를 인식해야합니다. 또한 이러한 의미론적인 지식을 자연어로 표현할 수 있어야합니다.
본 논문에서는 single joint model인 NIC를 제시합니다. image I를 입력하고, likelihood p(S|I)를 최대화하는 타겟 단어의 시퀀스 S를 출력합니다. NIC의 메인 아이디어는 머신번역의 구조를 활용합니다. 머신번역은 “encoder” RNN이 source sentence를 읽고 이를 fixed-length vector representation으로 바꾸면, “decoder” RNN이 그에 기반하여 target sentence 를 만들어 냅니다. 여기에 NIC는 encoder RNN을 CNN으로 대체합니다. CNN은 input image를 fixed-length vector로 임베딩해 이미지에 대한 우수한 representation을 만들어 낼 수 있습니다. 따라서, 이미지 분류를 목적으로 pre-train된 CNN의 last hidden layer를 decoder RNN의 input으로 넣어 sentence를 생성하는 구조입니다.

이 모델의 장점은 첫번째, 전체 neural net이 SGD를 통해 학습됩니다. 이전에 각각의 방법을 따로 합친 것과 달리 하나의 모델로 end-to-end 시스템입니다. 두번째, Vison과 language 모델의 SOTA 모델을 결합했습니다. 따라서 더 큰 corpora에 pre-trained되어 더 좋은 성능을 가질 수 있습니다.
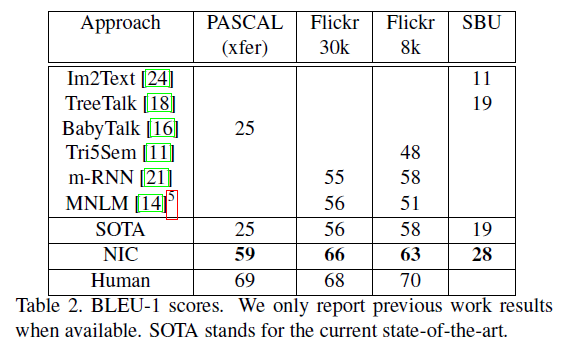
이 모델은 기존의 최상의 결과보다 훨씬 뛰어난 성능을 보여줍니다. Pascal dataset에서 기존의 모델의 BLEU 점수(높을 수록 좋음)가 25 였던 반면 NIC는 59점의 성능을 보여줬습니다(사람의 점수 69). Flickr30k에서 56에서 66으로, SBU에서 19에서 28로 성능이 향상되었습니다.
Model
이미지에 대한 설명을 생성하기 위해 neural과 probabilistic 프레임워크를 사용합니다. 다음의 식을 사용해, 입력 이미지가 주어졌을 때 정답 묘사(correct description)이 나올 확률을 directly maximize합니다. 모든 경우에 대해 input image I가 주어졌을때의 정답 묘사 S의 확률을 최대화 할 수 있는 parameter θ를 구하는 것입니다.

θ : 모수
I : 이미지
S : 정답 묘사(correct description)
S는 어떠한 문장이기 때문에 길이가 제한되어있지 않습니다. 따라서 chain rule을 사용해 S_0, ..., S_N까지의 확률을 결합확률로 나타내야 합니다. 여기서 N은 예시의 문장 길이입니다. train 과정에서 이미지와 정답 묘사가 (S,I)의 pair로 주어지고, 다음식의 로그 확률의 합에 따라 SGD를 사용해 최적화를 합니다. 즉 (I가 주어졌을때의 0번째 단어가 S_0일 확률) X (I, S_0이 주어졌을때의 1번째 단어가 S_1일 확률) X …의 형태로 로그 확률이 계산 됩니다.
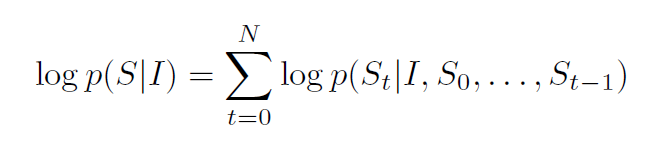
이 확률은 RNN으로 구현할 수 있습니다. t-1개의 단어가 고정된 길이의 hidden state나 memory, h_t로 표현됩니다. 이 memory는 새로운 input x_t이 들어오면 non-linaer function, f를 통해 업데이트 됩니다.
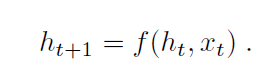
이 RNN 모델에 다음 두가지가 고려되었습니다.
1. 구체적으로 어떤 f를 사용할까
f는 번역과 같은 sequence task에 높은 성능을 보여준 LSTM net을 사용했습니다.
2. 이미지와 단어가 어떻게 input x_t로 들어갈까
이미지를 표현하기 위해서 object recognition과 detection에서 좋은 성능을 보여준 CNN을 사용했습니다.
단어는 embedding model로 표현되었습니다.
(word embedding은 단어를 랜덤한 값을 가지는 밀집 벡터로 변환한 뒤에, 인공 신경망의 가중치를 학습하는 것과 같은 방식으로 단어 벡터를 학습하는 방법입니다.)
1) LSTM based Sentence Generator
RNN의 미분사라짐과 미분폭발을 방지하기 위해서 LSTM을 사용했습니다. LSTM 모델의 핵심은 매 input 마다 업데이트 되는 memory cell C 입니다. 이 cell C는 3개의 gate가 각각 곱해지며 통제됩니다. gate가 1이면 값을 반영하고, 0이면 값을 반영을 하지 않는 형태입니다. 구체적으로 3개의 gate는 각각 현재의 cell 값을 잊을지 말지를 통제하는 forget gate(f), 어떤 input을 반영해줄지를 통제하는 input gate(i), 어떤 것을 output으로 내보낼지를 통제하는 output gate(o)가 있습니다.

이 gate, cell, output의 정의는 다음과 같습니다. 비선형의 sigmoid와 hyperbolic tangent h()를 사용합니다. m_t는 Softmax의 입력해 모든 단어에 대한 확률을 만듭니다.
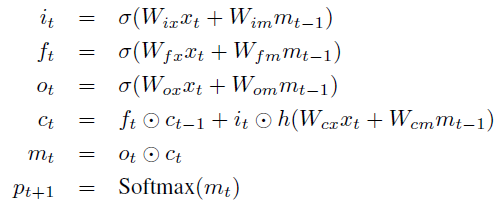
W : trained parameter
⊙ : product with a gate value
(1) Training
LSTM 모델은 이미지(I)와 이전의 단어들(S_0, ... , S_t-1)을 사용해 문장의 다음 단어를 예측합니다. t time일 때, 각각의 LSTM은 같은 모수와 output m_t-1을 공유합니다.
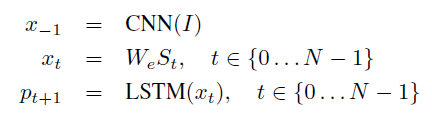
I : image
W_e : word embedding
S_t : 각각 dictionary size의 차원인 one-hot vector

S_0는 special start word, S_N은 special stop word로 문장의 시작과 끝을 구분합니다. 또한 각각의 단어 S에 word embedding W_e를 곱해줌으로써 CNN을 통한 image representation과 word가 같은 차원에 있도록 했습니다. 이미지는 LSTM에 이미지의 내용을 전달하기 위해 한번만(t = -1일때) input됩니다.
즉 첫번째 input, S_−1은 CNN(I)이고, 여기서 나온 hidden state가 두번째 input S_0와 합쳐져 결과적으로 output S_1과 새로운 hidden state를 만듭니다.

손실함수는 다음과 같이 각 step에서 correct word의 음의 로그 우도함수입니다. 이를 최소화 시키는 방향으로 LSTM의 parameter와 word embedding W_e, CNN의 image embedding을 하는 top layer를 학습합니다.

(2) Inference
문장을 만드는 다양한 방법이 있습니다. 첫번째 방법은 Sampling 입니다. p_1에 따라 첫번째 단어를 만들고 이를 다시 input으로 해 p_2를 만들고 이 과정을 special end-of-sentence token이 나올 때까지 또는 최대길이까지 반복하는 것이 Sampling입니다.
두번째 방법은 BeamSearch입니다. 매 time t까지의 k개의 best sentences set을 사이즈가 t+1인 문장을 생성할 후보군으로 고려합니다. 이 후보로 만든 t+1개의 문장 중 best k개의 문장을 반환합니다. 즉 상위 k개를 선택하고 이 과정을 반복하는 것이 BeamSearch입니다.
본 논문의 실험에서는 BeamSearch 방법(beam size= 20)을 사용했습니다.
Experiments
1) Generation Results
BLEU는 reference sentence와 얼마나 비슷한가를 평가하는 척도로, 구체적으로 몇개의 n-gram이 reference sentence와 겹치지를 통해 평가합니다. BLEU Score 값 비교결과 가장 좋은 성능을 보여줍니다.
2) Human Evaluation

NIC 모델을 사용한 Image captioning의 예시로 사람이 이미지에 대한 묘사를 4가지로 rating한 자료입니다. 2행1열의 사진에서 frisbee를 detect한 것이 놀랍습니다.
Conclusion
본 논문에서는 자동적으로 이미지를 보고 합리적인 묘사를 생성하는 모델 NIC를 제시합니다. NIC는 이미지를 compact representation으로 encode하는 Convolution neural network(CNN)과 대응하는 문장을 생성하는 Recurrent neural network(RNN)에 기반하고 있습니다. 몇개의 데이터셋에 실험 결과 질적으로 합리적인 문장을 생성했고 ranking metrics나 BLEU로 측정했을 때 양적으로 좋은 성능을 보여줬습니다. 데이터셋의 사이즈가 증가할 수록 성능이 증가했습니다.
더 나아가 비지도 데이터를 가지고(image만 있거나, text만 있거나) 성능을 높이는 방법 연구도 흥미로울 것입니다.
Reference
https://arxiv.org/abs/1411.4555
https://godongyoung.github.io/%EB%94%A5%EB%9F%AC%EB%8B%9D/2018/02/01/Show-and-Tell_A-Neural-Image-Caption-Generator-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0.html
https://mrsyee.github.io/nlp/2018/11/24/Show_and_tell/
'CV' 카테고리의 다른 글
| Image Captioning (0) | 2022.03.08 |
|---|