2022. 1. 18. 01:58ㆍRecommender System
잡케어 추천 알고리즘 경진대회에 참가했다. 고용정보원에서 주체하는 경진대회로 잡케어 서비스에 적용 가능한 추천 알고리즘 개발하는 것이 목적이다. 잡케어는 일자리를 탐색하는 구직자에게 구직자의 이력서를 인공지능 기술로 직무역량을 자동 분석하여 훈련, 자격, 일자리 상담에 활용할 수 있도록 지원하는 시스템이다.
한달동안 개인별 맞춤형 컨텐츠 추천 모델을 만들었다! 간략하게 공모전 과정에서 어떤 생각을 하고 어떤 시도를 해봤는지 남기려고 한다.
2022년 1월 1주차
팀을 구성하고 데이터와 변수에 대해서 파악했다.
-34개의 특성변수가 있고
-목적 변수는 컨텐츠 사용여부로 분류문제이다.
특성변수는 (1) 회원 속성 대한 변수, (2) 컨텐츠 속성에 대한 변수, (3) 회원과 컨테츠 속성의 매칭여부로 나눌 수 있었다.
분류기준이 세분화된 속성도 있었는데 다음과 같았다.
속성 D 코드 : 코드 - 세분류 - 소분류 - 중분류 - 대분류
속성 H 코드 : 코드 - 중분류 - 대분류
속성 L 코드 : 코드 - 세분류 - 소분류 - 중분류 - 대분류
우선 우선 RandomForestClassifier로 베이스모델을 구축했다.
그리고 XGBoost, CatBoost, LigthGBM을 사용해보고, GridSearch를 사용해 적합한 초모수를 찾았다. 과적합을 방지하기 위해서 교차검증과 중첩교차검증을 사용했다.
베이스라인이 성능이 좋아 tree 기반의 다른 모델를 사용해보려고 했다.
2022년 1월 2주차
데이콘 공모전의 경우 피쳐 엔지니어링이 중요한 요소이다. 예측에 도움을 주는 변수를 만들어 내는 것이 중요하다.
콘텐츠 속성과 사용자 선호속성이 일치하는 지의 여부로 각 속성마다 변수를 만들었다.
구직자에게 채용시기, 자소서 적는 시기, 면접시기 등 처럼 일자리를 구하는 과정에 이러한 은 중요한 의미를 가지고 그때마다 다른 콘텐츠를 필요로할 것이라고 생각해 월(Month) 변수, 그리고 시각(hour) 변수도 만들었다.
주어진 데이터를 가장 하위의 속성으로 나타나있기 때문에 제공된 속성코드를 기준으로 각각의 세분류, 중분류, 대분류 변수를 만들었다.
범주형 변수가 많아 one-hot encoding을 했다. 그 결과 변수가 100개가 넘어 너무 많아졌다. 모델을 돌리는 데 너무 많은 시간이 걸린다는 문제가 생겼다.
2022년 1월 3주차
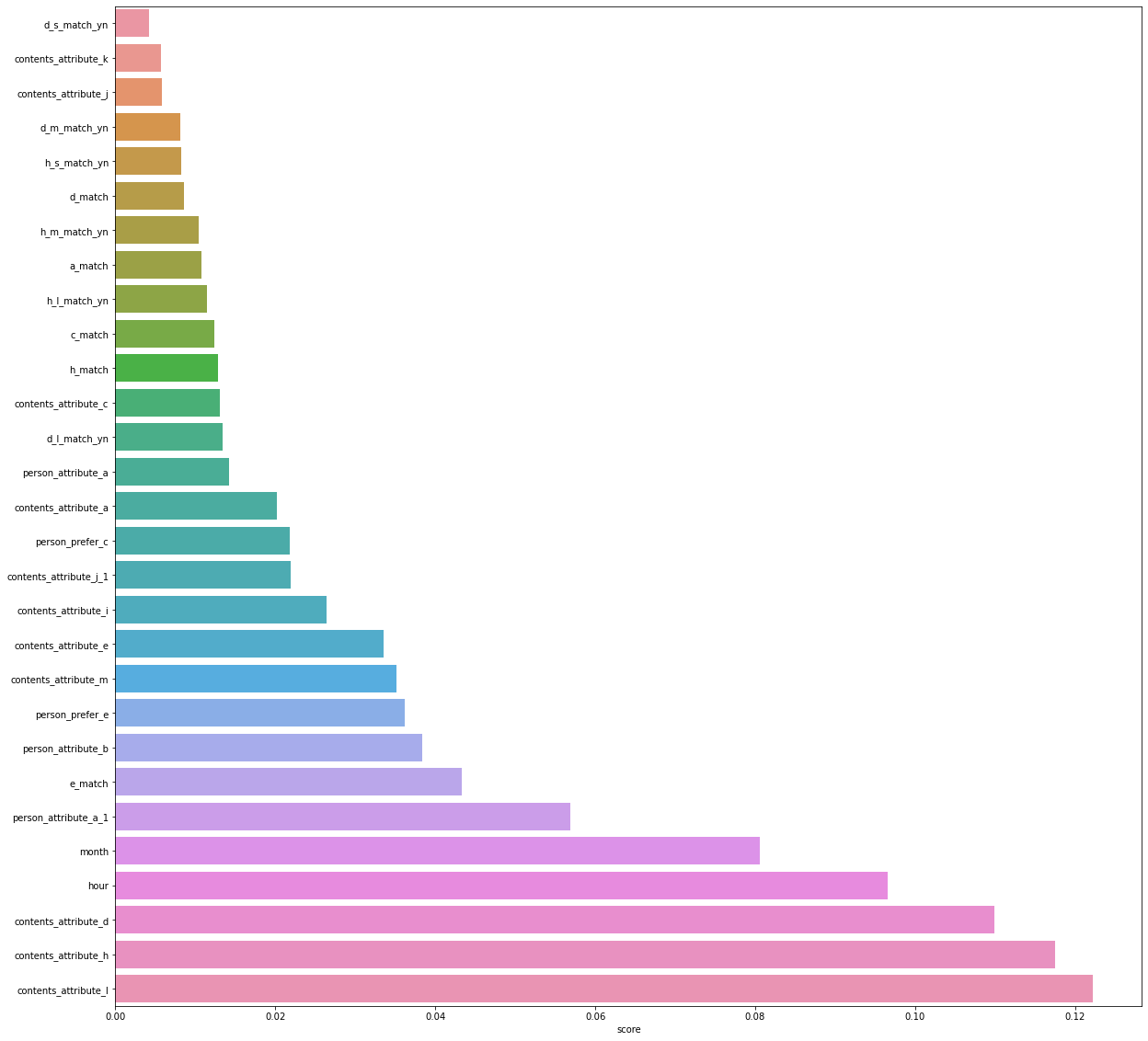

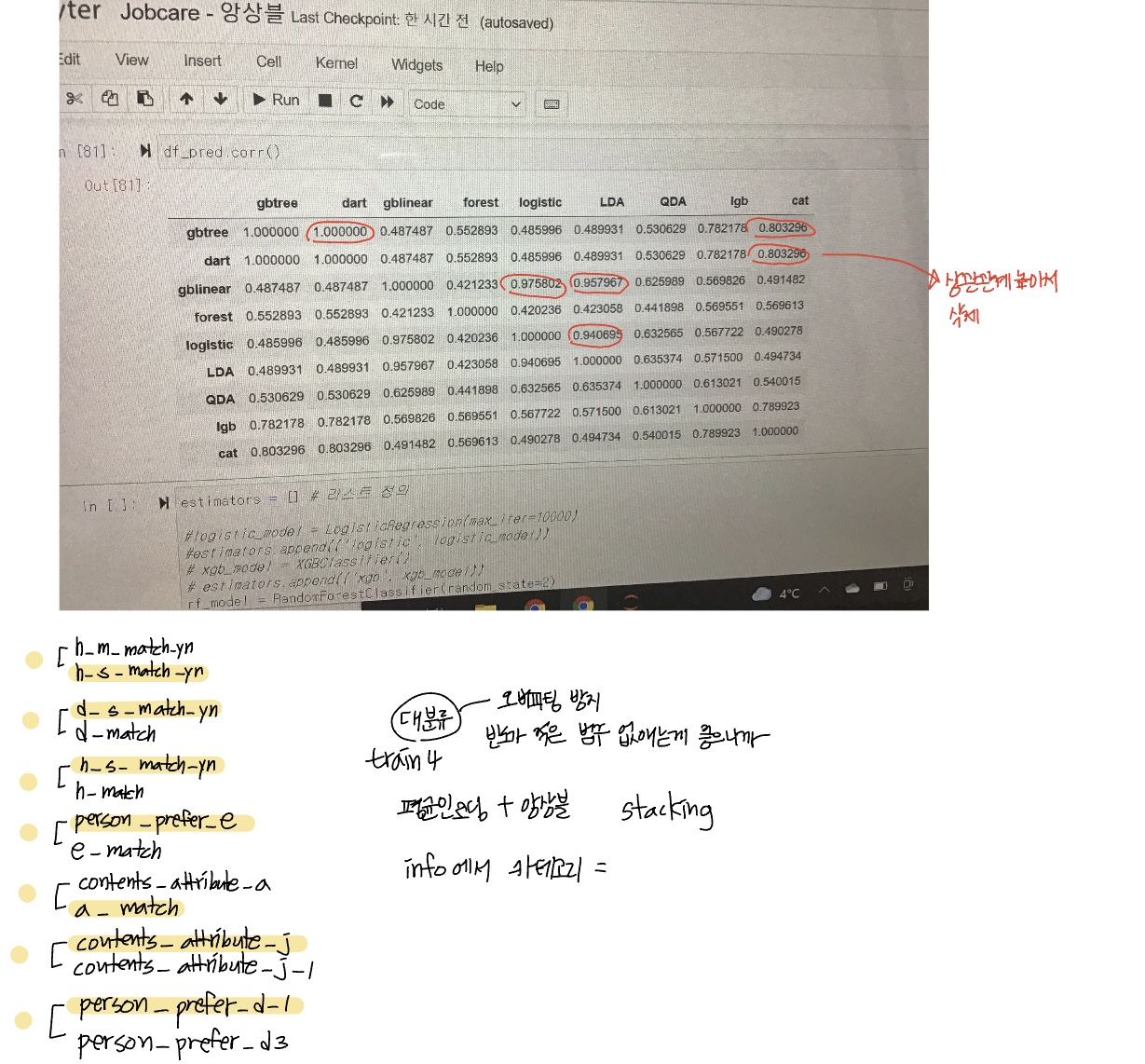
변수가 너무 많아 변수중요도에서 높은 변수 6개만 뽑아 모델에 적용하는 방법을 사용해봤으나 정확도가 이전보다 낮아졌다. 그래서 상관관계를 보고 상관관계가 0.80 이상인 변수를 찾고 변수중요도를 보고 중요도가 낮은 변수를 삭제했다. 또 분류 크기는 세분류 그리고 대분류 분리해서 각각 만들어서 모델의 성능을 확인해서 결정했다.
새로운 변수를 생성하고 삭제하고를 반복했다...!
2022년 1월 4주차
평균인코딩, 메타모형을 적용했고 성능이 크게 향상되었다.
TargetEncoding()
VotingClassifier()
VotingClassifier(voting='soft')
stacking
범주형 데이터 보다 범주별 목적변수의 평균 대체가 더 많은 정보를 내포하고 있기 때문에 성능이 오른 것 같다.
또 여러 모델을 모두 활용할 수 있는 앙상블학습, 스택킹의 효과도 좋았다.
f1 score가 평가 방식이었기 때문에 threshold 조정도 시도해보았다. https://jays-lab.tistory.com/31 여기를 참고했다.
4주차에 새로운 아이디어나 방법론을 많이 배워서 이를 더 활용해보지 못해 아쉬웠다. 초모수를 구하고 fit 시키는 데 시간이 생각보다 더 오래걸렸다. 더 성능을 올릴 수 있는 아이디어가 있었는데 시간이 부족했다ㅠㅠ 제출 기한이 지나고 추가로 제출해본 제출물의 성능이 가장 좋았다ㅎ
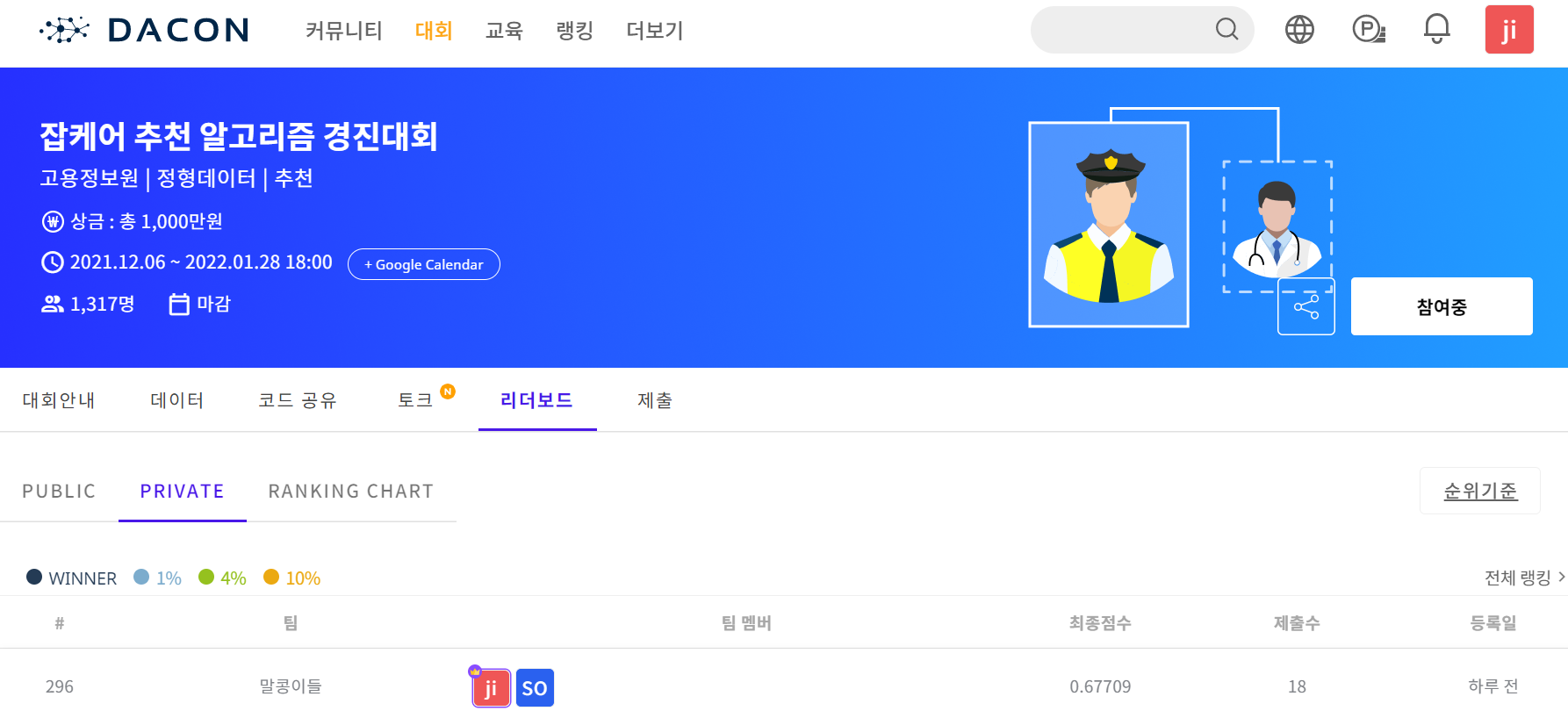
Private 296위로 22%에 들었다. 첫 데이콘 공모전이라서 아쉬움도 남았지만 수고했다!
'Recommender System' 카테고리의 다른 글
| 콘텐츠 기반 필터링(Content-based filtering) (0) | 2022.01.14 |
|---|---|
| Word2Vec을 활용한 추천시스템 (0) | 2022.01.12 |
| 잠재요인 협업필터링(latent factor collaborative filtering) (0) | 2021.08.25 |